PTC-Depth estimates temporally consistent metric depth using only a single camera and just how far it moved — no LiDAR needed. It works across RGB, NIR, and thermal imagery without any fine-tuning.
Abstract
Monocular depth estimation (MDE) has been widely adopted in the perception systems of autonomous vehicles and mobile robots. However, existing approaches often struggle to maintain temporal consistency in depth estimation across consecutive frames. This inconsistency not only causes jitter but can also lead to estimation failures when the depth range changes abruptly. To address these challenges, this paper proposes a consistency-aware monocular depth estimation framework that leverages wheel odometry from a mobile robot to achieve stable and coherent depth predictions over time. Specifically, we estimate camera pose and sparse depth from triangulation using optical flow between consecutive frames. The sparse depth estimates are used to update a recursive Bayesian estimate of the metric scale, which is then applied to rescale the relative depth predicted by a pre-trained depth estimation foundation model. The proposed method is evaluated on the KITTI, TartanAir, MS2, and our own dataset, demonstrating robust and accurate depth estimation performance.
PTC-Depth recovers metric-scale depth maps and accumulates temporally consistent 3D point clouds from monocular video using only wheel odometry.
How It Works
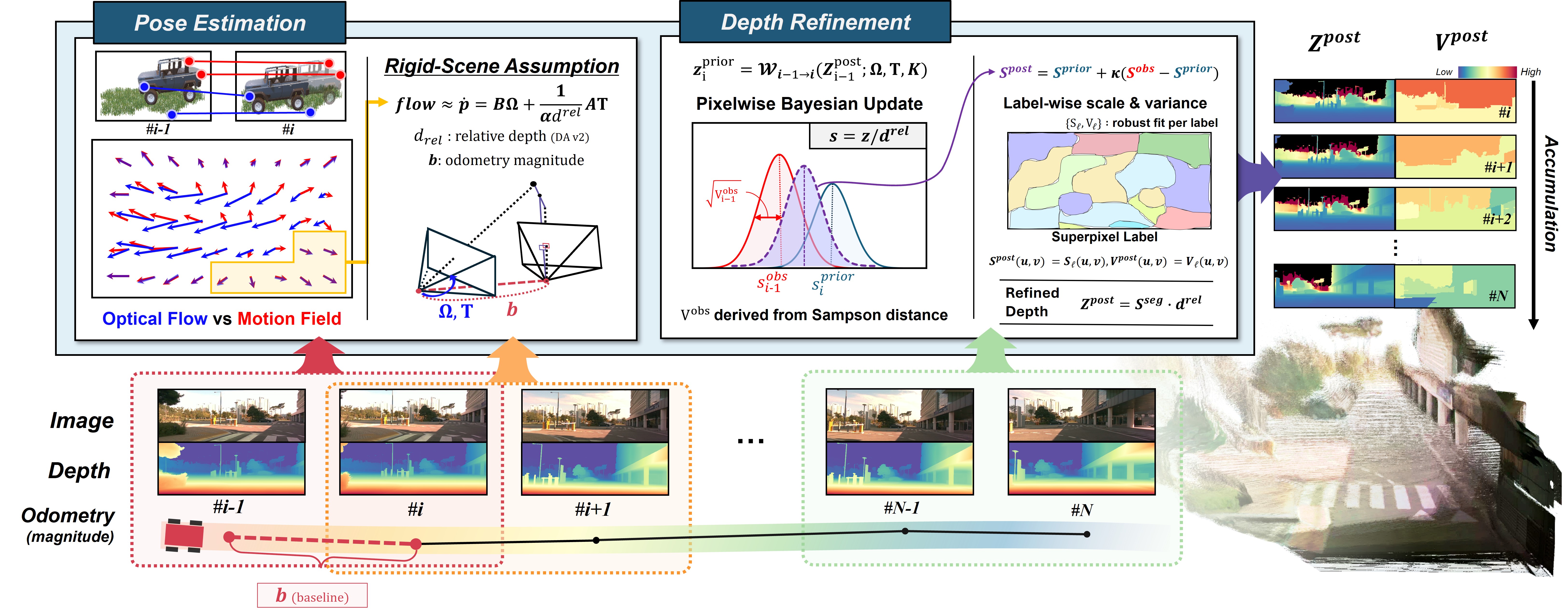
Given consecutive monocular frames and a scalar displacement (from wheel odometry or GPS), PTC-Depth estimates camera pose via optical flow and recovers metric scale. Sparse depth is obtained through triangulation and fused with a foundation model's relative depth prediction using recursive Bayesian updates. A superpixel-based spatial refinement further stabilizes the scale across regions, producing temporally consistent metric depth without any training or fine-tuning. For full details, please refer to the paper.
Quantitative Results
We evaluate PTC-Depth on 7 scenarios spanning RGB, NIR, and thermal imagery across 4 datasets. Our method requires only a monocular camera and a scalar displacement per frame — wheel odometry for our custom dataset, and GPS-derived displacement for KITTI, TartanAir, and MS2. No dataset-specific fine-tuning or additional depth sensors are used. PTC-Depth achieves the best or second-best accuracy on all out-of-distribution scenarios.
| Method | RGB | Thermal / NIR | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| KITTI | TartanAir | Roadside | Forest | MS2 | Roadside | |||||||
| AbsRel↓ | δ<1.25↑ | AbsRel↓ | δ<1.25↑ | AbsRel↓ | δ<1.25↑ | AbsRel↓ | δ<1.25↑ | AbsRel↓ | δ<1.25↑ | AbsRel↓ | δ<1.25↑ | |
| UniDepth | 0.047 | 0.977 | 0.503 | 0.176 | 0.465 | 0.201 | 0.444 | 0.088 | 0.205 | 0.698 | 0.394 | 0.245 |
| DA v2 | 0.171 | 0.773 | 0.513 | 0.372 | 0.494 | 0.177 | 0.418 | 0.336 | 0.405 | 0.187 | 0.527 | 0.193 |
| VDA | 0.356 | 0.321 | 0.599 | 0.342 | 2.198 | 0.010 | 1.339 | 0.041 | 0.590 | 0.078 | 2.275 | 0.011 |
| PTC-Depth | 0.137 | 0.877 | 0.427 | 0.688 | 0.309 | 0.725 | 0.480 | 0.520 | 0.247 | 0.700 | 0.570 | 0.527 |
Bold: best, underline: second best. All models use publicly available metric depth models.
Qualitative Comparison
We compare accumulated 3D point clouds from PTC-Depth against UniDepth and VDA. UniDepth produces accurate depth on KITTI (its training domain), but exhibits severe jitter and scale drift on unseen environments such as forests and thermal imagery. VDA maintains smoother temporal transitions, but its metric scale is often inaccurate, leading to distorted geometry. PTC-Depth produces geometrically consistent reconstructions across all scenarios.
PTC-Depth
◀
UniDepth
▶
Citation
@article{han2026ptcdepth,
title={PTC-Depth: Pose-Refined Monocular Depth Estimation with Temporal Consistency},
author={Han, Leezy and Kim, Seunggyu and Shim, Dongseok and Lee, Hyeonbeom},
journal={arXiv preprint arXiv:2604.01791},
year={2026}
}